基于Adaboost算法的驾驶员眨眼识别
眨眼是一种睁闭眼睛的生理活动,眨眼的速度会受疲劳程度、情感压力、行为种类、睡觉数量、眼睛受伤程度、疾病等因素影响[1~2]。眨眼识别是驾驶员疲劳检测的基础,本文采用 Adaboost算法[3][4][5]训练和检测眼睛睁闭状态,把睁眼和闭眼图片分类出来。
Adaboost算法
Adaboost是一种自适应 boosTIng算法,它的原理就是将一些简单的弱分类器 (矩形特征 )通过特定的训练需求 (一般为检测率和误检率的要求)组合成为一个强分类器,在训练和检测时每一个强分类器对待检测的矩形特征进行判决,将这些强分类器级联起来就可以生成一个准确的、快速的分类器。它的特点就是检测速度快,因为每一个强分类器都可以否决待检测的矩形特征,所以前面的强分类器就可以把大部分错误的特征给排除掉。
下面介绍Adaboost算法对强分类器的训练。本文正样本为包含各种姿态人眼的图片(睁眼、闭眼、带眼镜),负样本为不包含眼睛的任意图片。设输入的n个训练样本为:{(x1,y1),(x2,y2),......(xn,yn)},其中xi是输入的训练样本,yi∈{0,1}分别表示正样本和负样本,其中正样本数为 l,负样本数m。n=l+m,具体步骤如下:
(1) 初始化每个样本的权重w1,i∈D(i);
(2)对每个t=1,..., T(T为弱分类器的个数)
①把权重归一化为一个概率分布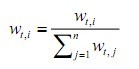
②对每个特征f,训练一个弱分类器hj计算对应所有特征的弱分类器的加权错误率![]()
③选取最佳的弱分类器ht(拥有最小错误率):et
④按照这个最佳弱分类器,调整权重![]()
其中ei=0表示被正确地分类,ei=1
表示被错误地分类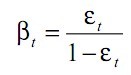
(3)最后的强分类器为: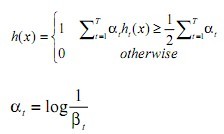
基于Adaboost算法的眨眼识别
要保证视频流中图像处理的实时性就必须采用特定的算法。Adaboost算法由于它特殊的算法模式,可以进行快速的目标检测,因此我们的人眼状态检测的定位,系统就选择了 Adaboost算法。基于Adaboost的眨眼识别系统主要包含两个模块:训练和检测。其中训练过程起着决定性的作用。
训练
样本的选择至关重要,包括两个方面,首先是样本源,本文采用BioID-EyeDatabase和AR人脸库(来源于网络)[6],样本库提供了人脸图片和人眼坐标,根据人眼坐标用Matlab编程来提取人眼。正样本从截取出的人眼图片中选取闭眼图片,负样本为剩下的睁眼图片。样本的训练过程就是按第2部分算法所阐述的方法选择弱分类器, 形成强分类器, 再由强分类器级联成为一个有效的分类器。在训练时给出检测率和误检率的要求,如检测率为0.99,误检率为0.3,若一共有n个强分类器,则最终的检测率为0.99n,最终的误检率为0.3n。
检测
检测就是根据训练所得到的分类器特征一般存储为.xml文件对输入图片进行检测。分类器是一个有若干个强分类器组成的级联分类器,检测结果是一系列的目标矩形,也就是图像中目标所在的位置。
实验结果分析
本文采用三种不同的负样本选择方法,进行了三次对比实验。
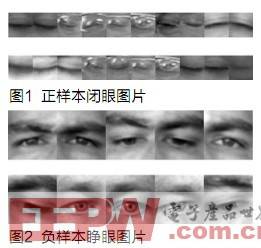
实验一:正样本582张闭眼图片,归一化为24×24,负样本1285张睁眼图片,正负样本如图1、图2所示,实验结果如图3所示。
从实验结果可以看出睁眼图片中把眉毛误检为闭眼图片,原因是负样本数量和种类少,导致误检率高。

本文提出了一种新的负样本选择方法,这样给我们扩展训练样本量提供了很大的帮助,就是在Opencv[7]中修改程序,利用已经训练好的分类器,来检测大量视频图片,把误检的图片保存下来加入到负样本中来作为下次训练的新的负样本,并继续训练,然后利用下次训练好的新的分类器来继续添加负样本。负样本截取软件界面如图4所示。
实验二:正样本582张闭眼图片,与实验一相同,负样本2300张,其中除了实验一中的负样本,还包括从负样本截取软件中收集到的误检图片。添加的负样本如图5所示。

实验结果如图6所示。

从实验结果可以看出睁眼图片中把两内眼角以外一定范围误检为闭眼,说明负样本的种类还是没有达到要求。所以继续利用负样本截取软件收集误检到的图片作为负样本。

实验三:正样本582张闭眼图片,与实验一相同,负样本为2965张,其中除了实验二中的负样本,还包括从负样本截取软件中收集到的误检图片。添加的负样本如图7所示。

实验结果如图8所示。
从实验结果中可以看出利用最终的负样本训练生成的分类器能有效的区分出睁眼和闭眼状态,误检率大大降低,说明这样的负样本选择方法行之有效。
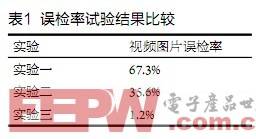
三个实验结果误检率比较如表1所示。误检率为错误检测的图片数除以图片总数。
结语
本文通过实验,提出了一种新的负样本选择方法,这样给我们扩展训练样本量提供了很大的帮助,即应用一个负样本截取软件,通过载入先前训练好的分类器,不断的收集误检的部分来添加进负样本中,作为下次训练的新的负样本,训练新的分类器。不断循环重复这个步骤,直到达到能产生有满意效果的分类器。从三个实验结果看出误检率逐渐减少,证明了方法的有效性。在以后的实验中继续采用层层迭代的方式,不断利用训练好的新的分类器来增加负样本,直到训练出更加精确的分类器,为后续判断汽车驾驶员疲劳检测做铺垫。