随着互联嗍技术的快步旋展,在互联削上传播的数据类犁逐渐增多。视频会议系统应运而生,^娄的沟通和交流,土蔓采用听和髓曲种方式,语音的传输成为衡最视频会议系统性能最重要的项指标。同此,对视频会议系统中的混音算法进1717『究具有重要意义。
终端对卅音信号的处理必须解决的问题是多路的酐首数据怎样在本地进行混音以及播放。它会受到自身同步。延时,与视频同步等多方的影响,在实际的应用中,语音经混合后对声卡缓冲区的溢出是其最大的问题。
这里介绍种混音结构,/A~ WJ改进的混音算法。在混音的质最、艘卓、滞山率、叫延及扩展性方而和现有的混音算法进行J比较。实验结果表明,该算法结音TA娄语音的特性,揪据小同场景的需求,在抑制混音溢IⅡ的同时,捉苛混音的质最,降低时延,具有很好的实用潜力。
1、混音算法分析
声音足由物体振动所产生的一种压力波。响度、音调和音色是声音的三个上要特征。在自然界中,人耳听见的语音来自四而八方声音的叠加。对于视频会议系统来说,需要将来自再处的语首数据在时域进行混合。语音信号的抽样及量化都放在声卡芯片上。常用的声卡为16位,帚化粘度多为16 bit.在众多操作系统如Linux中,声卡缓冲区的数据类掣通常为.iLmed short,范围在-32768-32767。多路混音后,幅值有可能超小声卡可接受的范罔而造成声音的失真。以上几种常见的解决办法。
(1)直接箝位法
混合后语音强度超出缓冲区数据类犁范同时,以最大情值来替代。这样阿接筘位会造成讯音波形的人为削峰,在破坏语音信号特性的同叫会促使噪音的产生。
(2)均佰化混音
均值化混音在将异路讲肯进行叠加之后,并除以棍音的路数来保证混音后小溢出。但随着混音路数的增加,在多个混音嫦小在同一时同发声的情景时,来自任一方的讲音信号将被多路均分,造成音最较小而小能辨识。
(3)对齐混音
可以说足均值混肯的娈型,这里上安分J强对齐和弱对齐。在强对齐中,对声强较大的混音路给予较大的混音权重,原话音较大的浒音路得划增蝎,缺点足淹没r脯较小的H}音。弱对齐对声强较小的混音路给予较大的混音权重。这样首最较小的混音路酣得到放大,跳点足同时也放大Jr背景噪音。
以上算法虽然简单,但都存在镒出榆删及混音质最方而的问题。下而介绍一种新掣改进的混音方案及算法。
2、改进的混音算法
在基于SIP的视频会议系统中,根据信令分旋和媒体混合的小同,有多样的构成方式”2]。就媒体流混合方式来说,有集中式混合与终端混音之分。
这里设计如图1的分布式混音模型,相比集中式混音,服务器端不进行媒体流的处理,而只执行会议系统的管理策略。终端接到分发过来的湃音数据,进行解码处理后,即开始混音。这种模式小混入终端自身出菠的湃首包,小受回声的影l~。综合来看,这样的棍音系统复杂度适中,可减轻会议服务器的压力。延时较集中式混音有减少,对于实时应用的系统来说,性能的提升压力很大。
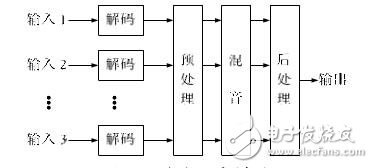
图1分布式混音模型
这里设计为面向中小企业及学校教学用视频会议系统,参与人数在5 人以下。会议参与者共同发声的可能性较小,强烈溢出的儿率也比较小。因为语音信号具有短时的相关性,即这里所说的一个帧。这时间通常在10 ms 到30ms,里在设计混音算法时兼顾溢出及平滑处理,并且以语音帧为单位,算法流程如下
①初始化衰减因子f _see 为1;
②统一数据内的信皂,包括最大峰值的绝对值,一帧内的短时能最放过零率,
③将最大绝对峰值与i6 bin数挥宽度做比较,判断是舌溢山。如果y她求出台适的衰减罔r并更新(f see-Ma/sos,Max为最大喃值绝对值一s为最大绝对峰佰与日f一帧衰减田f的乘积),并邝最新的最减冈r与本帧数据相乘,输出剑声卡缓冲,
④如果没有镒帆,则根据短时能最和过零率的训算来动态改变衰减因子。并用最新的衰减因子来输出本帧数据到声卡缓冲;
⑤读取下一帧,再次执行第2步。

对溢出的判定,文献【4]中所采用的衰减阿n±,对每帧的每个样本和衰减冈J相乘。在常用的定点处理器中,较多的乘除法将会大吊消耗CPU的资源,带来时延。随意更改样本问相对大小会导致混厶J语音的失真。这ltrXil按帧对研音信号进行时城平}目处理,它小会d业语音的内容。通过平滑处理, 帧的滑音信息按照比侧缩小,语音特征参数
在样本溢出并进行衰减处理后,需要个机制来进行有效补偿。这里十^先衰减冈r进行iH-化业理,将衰减冈ff see映射成320等分进行运算,用牲颦最ppp来表达,即f_se e-Tppn 20,ppp为320与f see相乘后鞭粘。由于在语音编解码上采用r C17ci ~i女,A律抓扩,增强对小信号的讹精度,对小信号的训节较J半富州。这里设置ppp的增减上下限为160到320。在睦剥混音的过程中,使卅肯处于小信号敏培的部位,避丌粗糙的大信号,调节至人耳舒适的范同。
归一化的衰减冈r ppp的增减依押语音信号过零率的判断,蚍及相邻曲桢短时能最的比较。在第4步进行动忐衰减罔r的训算叫,参考第2步对语音人声的短日-能最放过零率的榆删。根杯文献『7]中的经验佰,取iO ms帧的语音过零率闽值为4。“i傧际榆删的过零率庄4蚍E时,粗略判定其为许音信号帧,之后对相邻语音信号帧进行短叫能最的比较,”1卅H的短时能景缩小叫逐步增大衰减网f,”语音的短叫能帚增大叫逐步缩小衰减田Jf-,这种对衰减田j’的动忐废复,将增慢棍音后信号的收敛性及健壮性。
这里设计为而向中小企业及学校教学用视频会议系统,参与人数在5人以下。会议参与青共同技声的可能性较小,强烈滞出的儿率也比较小。冈为语音信号具有短时的相关性,时问通常在io ms到30 ms,即这里所随的个帧。这里在设讨混音算法叫兼顾镒出发平柑处理,并且以语音帧为单位,算法‘流程如下:
3、嵌入式实现及结果分析
为了对比改进的混音算法的性能,将写好的混音算法放在视频会议系统实际运行的嵌入式环境下来测试。该款处理器为TI 公司的DaVinci 系列片上系统DM6446-594 异构双核处理器。其中混音算法放在ARM 端运行,该ARM 核为ARM9 系列,运行频率为297M。这里共采集3 路语音,一路为纯背景噪音,一路为人声,声强靠近溢出位置,另一路为人声,声强适中。两路人声均采用较难区分的男声。测试结果如图2、图3和图4所示。

由混音后时域波形图可见,图2 为采用单纯溢出衰减算法的混音过程。随着混音过程的推进音量逐渐减小。当某一刻出现混音高峰时,造成极小的哀减因子,音量变得很小而不可恢复。图3 为参考文献[5]中采用的定步长单增恢复衰减因子的方法,这种混音方式会使得音量一直维持在最大值附近,声音刺耳,噪音强烈。它增加了下次混音的溢出儿率,增加了溢出检测和新的哀减因子计算,消耗资源,带来时延。图4 为这里改进的算法,采用按帧衰减,区别于文献[5]的按样本处理,减少了定点处理器的乘除法操作,提升了计算性能。其哀减因子采用归一化细分,并设置上下限。采用短时能量及过零率来对人声识别并动态更新衰减因子。该混音效果听起来平滑,噪音很小、无爆破音,混音后完全没有溢出现象发生。
4、结语
这里提出了按语音信号特征,以语音帧为单位的衰减因子法解决混音溢出问题,在算法上进行改进,提升了溢出处理的性能。并且提出了用短时能量及短时过零率来对人声语音进行粗检测及衰减后的补偿恢复,提升了混音质量。用户可依据网络环境对两种算法进行搭配选择。通过在定点处理器ARM9上的实现以及结果分析证明,该算法的性能及效果较好。